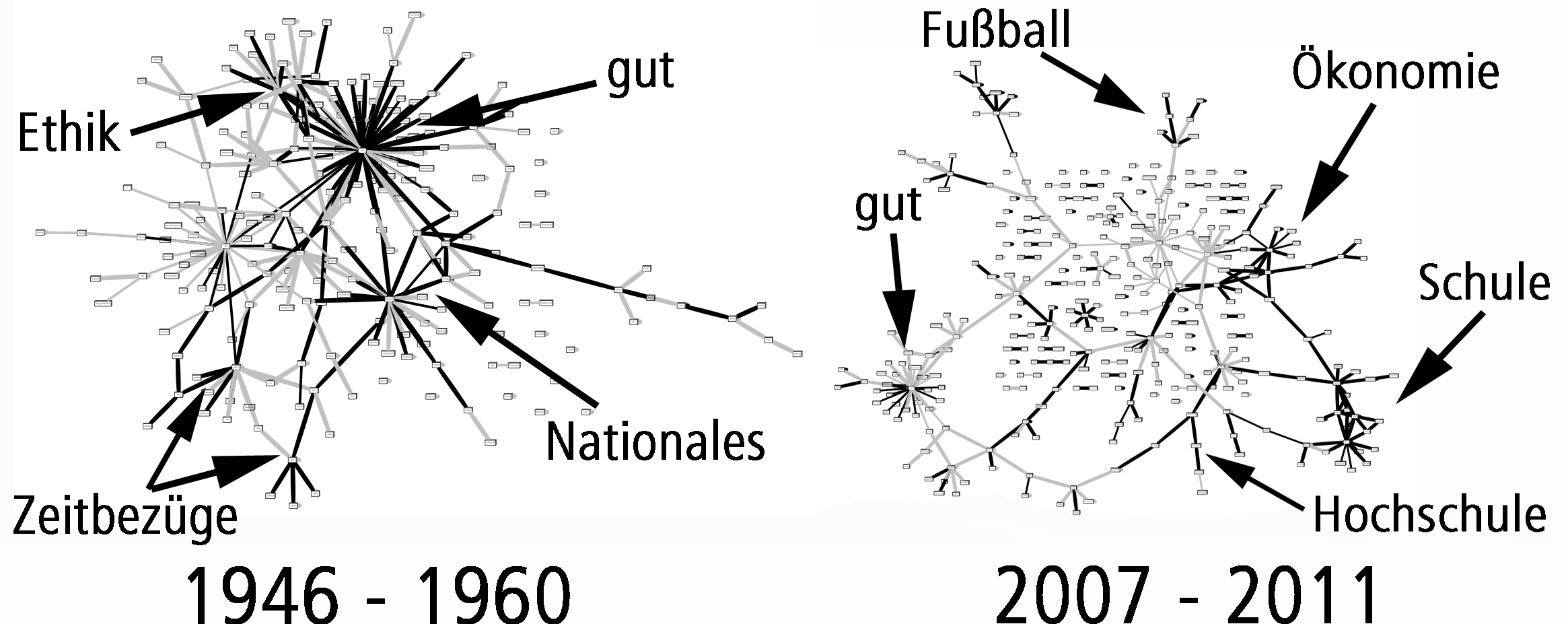
In Janoschs Kinderbuch „Post für den Tiger“ gründet der Hase mit den schnellen Schuhen einen Briefzustellservice und stellt die anderen Hasen aus dem Wald als Briefträger ein. In einer kurzen Ansprache macht er sie mit ihren Pflichten vertraut: „Ihr müsst […] schnell und schweigsam sein. Dürft die Briefe nicht lesen und das, was darin steht, niemandem erzählen. Alles klar?“ Und die Hasen mit den schnellen Schuhen antworteten „Alles klar!“ und alles war klar.
Der Hintersinn, mit dem Janosch seinen Hasen das Lesen der Briefe verbieten und im gleichen Atemzug betonen lässt, dass man deren Inhalt aber keinesfalls weitererzählen dürfe, ist der Chuzpe vergleichbar, mit der uns Geheimdienste und E-Mail-Provider wie Google oder Yahoo erklären, dass sie unsere Mails nicht lesen. Dabei haben sie nicht mal unrecht: Sie lesen unsere E-Mails ja wirklich nicht. Sie scannen und filtern und analysieren sie nur!
Nur Fliegen ist schöner…
Mit dem Flugzeug zu reisen hat bei allen Vorzügen einen entscheidenden Nachteil: Keine andere Form des Reisens normiert die Passagiere so weitreichend wie eine Flugreise. Sie erlaubt den Reisenden nur eine bestimmte Menge Gepäck in vorgeschriebener Form, weist ihnen einen engen Raum zu, den sie auch nur zu ganz bestimmten Zwecken verlassen dürfen, zwingt auf visuelle Signale hin zum Anschnallen, zwingt zum Ausschalten von Geräten und — indem das Entertainment-Programm unterbrochen wird — zum Zuhören bei allen Ansagen. Und keine andere Form des Reisens kennt derlei Sanktionen, wenn man sich der Normierung widersetzt: abhängig vom Land können einem Raucher auf der Bordtoilette Strafen vom Bußgeld bis zur merhmonatigen Gefängnisstrafe blühen. Die Annehmlichkeit der schnellen Überbrückung von Entfernungen zu einem noch erträglichen Preis wird also durch die Akzeptanz einer weitgehenden Normierung erkauft.

Vorrichtung zur erkennungsdienstlichen Behandlung, Gedenkstätte Bautzner Straße Dresden
Doch damit Passagiere eine Flugreise überhaupt antreten dürfen, müssen sie teilweise als erniedrigend empfundene Kontrollen über sich ergehen lassen. Kontrollen gibt es auf ganz unterschiedlichen Eskalationsstufen.
Unterscheiden kann man erst einmal zwischen solchen, die man selbst mitbekommt, und solchen, die im Hintergrund ablaufen. Ein Beispiel für eine Kontrolle, die meist gar nicht in unser Bewusstsein vordingt, ist das Durchleuchten der Koffer.
Man kann Kontrollen weiterhin danach unterscheiden, ob sie rein maschinell durchgeführt, mit Hilfe von Maschinen, die von Menschen überwacht werden, oder von Menschen selbst. Muss ich durch einen Metalldetektor gehen oder an einer Kamera vorbei, die zur Prävention einer Vogelgrippe-Pandemie bei der Einreise meine Temperatur misst, dann empfinde ich das als weniger unangenehem, als wenn jemand hinter dem Bildschirm eines Gerätes sitzt, der ein Röntgenbild vom Inhalt meines Handgepäcks zeigt. Gänzlich unangenehm empfinde ich es, wenn mein Handgepäck vom Sicherheitspersonal geöffnet und durchwühlt wird.
Weiter kann man Kontrollen danach unterscheiden, ob jeder davon betroffen ist oder nur Auserwählte. Als ich noch mit Rucksack reiste, schnupperten am Gepäckband bei der Ankunft häufiger Drogenhunde an meinem Gepäck, geführt von Polizisten, die wie zufällig in meiner Nähe herumstanden. Und wer kennt es nicht, in eine als „Kabine“ bezeichnete Trennwandbucht gewunken und abgetastet zu werden?
Je näher die Kontrollen an meinen Körper heranrücken, je personenbezogener sie werden, als desto unangenehmer empfinde ich sie. Die maschinelle, körperferne Kontrolle außerhalb meines Gesichtsfeldes, von der alle Passagiere gleichermaßen betroffen sind, finde ich hingegen am wenigsten störend. Und so effizient und distanziert wie das automatische Durchleuchten unserer Koffer so diskret und rücksichtsvoll scannen die Geheimdienste unsere E-Mails.
Von Gepäckkontrollen und Mail-Filtern
Die Geheimdienste lesen nicht unsere E-Mails. Sie lesen sie nicht in dem Sinn, wie unser Gepäck am Flughafen nicht durchsucht, sondern nur durchleuchtet wird.
Die Geheimdienste lesen unsere E-Mails auch nicht massenhaft. Sie lesen sie so wenig massenhaft, wie am Flughafen jeder in eine separate Kabine gewunken und abgetastet wird, sondern nur ausgesuchte Passagiere.
Die Geheimdienste lesen unsere E-Mails auch nicht, um Verdächtige zu identifizieren. Ganz so wie im Flughafen nur jener in die Kabine muss, bei dem die Metalldetektoren anschlagen, so filtern die Geheimdienste unsere E-Mails automatisch, und das sogar in einem mehrstufigen Verfahren. Und Filtern ist nicht Lesen. Und mal ehrlich: wer hat schon was dagegen, wenn E-Mails gefiltert werden? Wer nicht seinen eigenen Mailserver betreibt, dessen E-Mails durchlaufen automatisch Filter, Spamfilter. Und keiner würde behaupten, dass seine E-Mails vom Spamfilter „gelesen“ werden.
Nein! Die Geheimdienste lesen unsere E-Mails nicht. Sie lesen sie höchsten ausnahmsweise, wenn sie beim Abtasten auf etwas Auffälliges stoßen, wenn der Metalldetektor Alarm schlägt, die Drogenhunde anschlagen oder der Sprengstofftest positiv ausfällt.
Lesen ist etwas ganz anderes
Lesen, im engeren Sinn, ist nämlich etwas ganz anderes als das, was etwa der BND bei der strategischen Überwachung des Fernmeldeverkehrs macht. Lesen ist eine aktive Konstruktion von Textsinn, eine Interaktion von Texteigenschaften und Leser. Der Textsinn ist ein kommunikatives Phänomen, das aus einer Leser-Text-Interaktion resultiert. Und weil jeder Leser und jede Leserin anders ist, sich mit anderem Vorwissen und anderer Motivation ans Lesen macht, kann der Textsinn bei jeder Lektüre ein anderer sein. Von einem Computer erwarten wir allerdings, dass er bei gleichem Algorithmus bei jeder Textanalyse immer zum gleichen Ergebnis kommt. Was der Computer macht, ist also kein Lesen, zumindest nicht im emphatischen Sinn.
Aufklären, Scannen und Filtern
Was die Geheimdienste tun, das trägt den Namen „Aufklärung“, präziser „strategische Fernmeldeaufklärung“. COMINT, Communications Intelligence, so der englische Name, ist ein Teilbereich der Signals Intelligence (SIGINT) und dient dem Erfassen und Auswerten verbaler und nonverbaler Kommunikation die über Radiowellen oder Kabel übertragen wird. Typische Funktionen innerhalb der Fernmeldeaufklärung sind Scanning (liegt ein Signal im Sinne einer groben Metrik vor?), automatische Analyse (enthält das Signal relevante Informationen?), Aufzeichnung und strukturierte Speicherung und Aggregierung.
„Scannen“ hat neben der engen COMINT-Bedeutung im Englischen zwei weitere Verwendungsweisen. Einerseits bedeutet es die genaue Inaugenscheinnahme mit dem Ziel der Entdeckung einer Eigenschaft („look at all parts of (something) carefully in order to detect some feature“), andererseits ein oberflächliches Durchschauen eines Dokuments, um eine bestimmte Information daraus zu extrahieren („look quickly but not very thoroughly through (a document or other text) in order to identify relevant information“, New Oxford American Dictionary). In beiden Fällen bedeutet aber „Scannen“ jedoch etwas anderes als „Lesen“. Während Lesen in seiner emphatischen Bedeutung nämlich auf die Rekonstruktion eines ganzheitlichen Textsinns zielt, sucht man beim Scannen nur nach einer bestimmten Information oder einem bestimmten Merkmal, ohne den Anspruch zu haben, dem Textganzen gerecht zu werden.
Eine im Kontext der Überwachungsapologetik gerne gewählte Metapher ist auch die des Filterns. Filtern bedeutet, Stoffe, Flüssigkeiten, Signale o.Ä. durch ein durchlässiges Medium zu leiten, das jedoch bestimmte Anteile zurückhält. Und so heißt es in der „Unterrichtung durch das Parlamentarische Kontrollgremium“ über die Durchführung sowie Art und Umfang der Maßnahmen nach dem G 10-Gesetz für den Zeitraum vom 1. Januar bis 31. Dezember 2011:
„Der Aufklärung unterliegt […] lediglich ein eingeschränkter Teil internationaler Verkehre, der automatisiert stark gefiltert wird. Nur ein geringer Anteil dieser E-Mails wird überhaupt manuell bearbeitet. […] Der deutliche Rückgang im Jahre 2011 ist auch darauf zurückzuführen, dass der BND das von ihm angewandte automatisierte Selektionsverfahren auch vor dem Hintergrund der Spamwelle im Jahre 2010 zwischenzeitlich optimiert hat.“
Automatisierte Selektion ist völlig harmlos, das impliziert der Bericht des Kontrollgremiums, manuelle Bearbeitung hingegen erwähnenswert. Es ist wie mit den Kontrollen am Flughafen.
Wann beginnt der Eingriff in Grundrechte?
Was zwischen Netzaktivisten und Sicherheitspolitikern offenbar umstritten ist, ist also die Frage, ab wann denn von einem Grundrechteeingriff gesprochen werden kann: beim Scannen, bei der Aufzeichnung, bei der automatischen Analyse oder erst bei der personenbezogenen Auswertung („manuelle Bearbeitung“)?

Zellenspion, Gedenkstätte Bautzner Straße Dresden
Mit dieser Frage hat sich das Bundesverfassungsgericht in seinem Urteil vom 14.7.1999 beschäftigt, das 2001 zur bis heute geltenden Neuregelung des G 10-Gesetzes, des Gesetzes zur Beschränkung des Brief-, Post- und Fernmeldegeheimnisses, geführt hat.
Darin zeigt sich das Bundesverfassungsgericht durchaus sensibilisiert für die Folgen des automatisierten Beobachtens des Datenverkehrs:
„Die Nachteile, die objektiv zu erwarten sind oder befürchtet werden müssen, können schon mit der Kenntnisnahme eintreten. Die Befürchtung einer Überwachung mit der Gefahr einer Aufzeichnung, späteren Auswertung, etwaigen Übermittlung und weiteren Verwendung durch andere Behörden kann schon im Vorfeld zu einer Befangenheit in der Kommunikation, zu Kommunikationsstörungen und zu Verhaltensanpassungen, hier insbesondere zur Vermeidung bestimmter Gesprächsinhalte oder Termini, führen. Dabei ist nicht nur die individuelle Beeinträchtigung einer Vielzahl einzelner Grundrechtsträger zu berücksichtigen. Vielmehr betrifft die heimliche Überwachung des Fernmeldeverkehrs auch die Kommunikation der Gesellschaft insgesamt. Deshalb hat das Bundesverfassungsgericht dem – insofern vergleichbaren – Recht auf informationelle Selbstbestimmung auch einen über das Individualinteresse hinausgehenden Gemeinwohlbezug zuerkannt (vgl. BVerfGE 65, 1 ).“ (BVerfG, 1 BvR 2226/94 vom 14.7.1999, Absatz-Nr. 234)
Und die Richter stellen klar, dass der Eingriff in Grundrechte nicht erst bei der manuellen Auswertung beginnt sondern schon beim Erfassen:
„Da Art. 10 Abs. 1 GG die Vertraulichkeit der Kommunikation schützen will, ist jede Kenntnisnahme, Aufzeichnung und Verwertung von Kommunikationsdaten durch den Staat Grundrechtseingriff (vgl. BVerfGE 85, 386 ). Für die Kenntnisnahme von erfaßten Fernmeldevorgängen durch Mitarbeiter des Bundesnachrichtendienstes steht folglich die Eingriffsqualität außer Frage. […] Eingriff ist daher schon die Erfassung selbst, insofern sie die Kommunikation für den Bundesnachrichtendienst verfügbar macht und die Basis des nachfolgenden Abgleichs mit den Suchbegriffen bildet. […] Der Eingriff setzt sich mit der Speicherung der erfaßten Daten fort, durch die das Material aufbewahrt und für den Abgleich mit den Suchbegriffen bereitgehalten wird. Dem Abgleich selbst kommt als Akt der Auswahl für die weitere Auswertung Eingriffscharakter zu. Das gilt unabhängig davon, ob er maschinell vor sich geht oder durch Mitarbeiter des Bundesnachrichtendienstes erfolgt, die zu diesem Zweck den Kommunikationsinhalt zur Kenntnis nehmen. Die weitere Speicherung nach Erfassung und Abgleich ist als Aufbewahrung der Daten zum Zweck der Auswertung gleichfalls Eingriff in Art. 10 GG.“ (BVerfG, 1 BvR 2226/94 vom 14.7.1999, Absatz-Nr. 186ff)
Und wann ist dieser Eingriff gerechtfertigt?
Gleichzeitig aber sieht das Bundesverfassungsgericht die von Außen drohenden Gefahren als wesentlichen Grund, der geeignet ist, Grundrechtseinschränkungen zu gestatten:
„Auf der anderen Seite fällt ins Gewicht, daß die Grundrechtsbeschränkungen dem Schutz hochrangiger Gemeinschaftsgüter dienen. […] Die Gefahren, die ihre Quelle durchweg im Ausland haben und mit Hilfe der Befugnisse erkannt werden sollen, sind von hohem Gewicht. Das gilt unverändert für die Gefahr eines bewaffneten Angriffs, aber auch, wie vom Bundesnachrichtendienst hinreichend geschildert, für Proliferation und Rüstungshandel oder für den internationalen Terrorismus. Ebenso hat das hinter der Aufgabe der Auslandsaufklärung stehende Ziel, der Bundesregierung Informationen zu liefern, die von außen- und sicherheitspolitischem Interesse für die Bundesrepublik Deutschland sind, erhebliche Bedeutung für deren außenpolitische Handlungsfähigkeit und außenpolitisches Ansehen.“ (BVerfG, 1 BvR 2226/94 vom 14.7.1999, Absatz-Nr. 235, 238)
In seiner Abwägung kommt das Bundesverfassungsgericht zu dem Ergebnis, dass die verdachtslose Überwachung des Fernmeldeverkehrs im und mit dem Ausland durch den Bundesnachrichtendienst und damit der vorher formulierte Eingriff in die Grundrechte der Bundesbürger gerechtfertigt ist:
„Die unterschiedlichen Zwecke rechtfertigen es aber, daß die Eingriffsvoraussetzungen im G 10 anders bestimmt werden als im Polizei- oder Strafprozeßrecht. Als Zweck der Überwachung durch den Bundesnachrichtendienst kommt wegen der Gesetzgebungskompetenz des Bundes aus Art. 73 Nr. 1 GG nur die Auslandsaufklärung im Hinblick auf bestimmte außen- und sicherheitspolitisch relevante Gefahrenlagen in Betracht. Diese zeichnet sich dadurch aus, daß es um die äußere Sicherheit der Bundesrepublik geht, vom Ausland her entstehende Gefahrenlagen und nicht vornehmlich personenbezogene Gefahren- und Verdachtssituationen ihren Gegenstand ausmachen und entsprechende Erkenntnisse anderweitig nur begrenzt zu erlangen sind. Der Bundesnachrichtendienst hat dabei allein die Aufgabe, zur Gewinnung von Erkenntnissen über das Ausland, die von außen- und sicherheitspolitischer Bedeutung für die Bundesrepublik Deutschland sind, die erforderlichen Informationen zu sammeln, auszuwerten und der Bundesregierung über die Berichtspflicht Informations- und Entscheidungshilfen zu liefern.“ (BVerfG, 1 BvR 2226/94 vom 14.7.1999, Absatz-Nr. 241)
Eine Rolle bei der Abwägung hat offenbar auch gespielt, dass die Anzahl der überwachten Telekommunikationsbeziehungen verglichen mit der Gesamtzahl aller oder auch nur der internationalen Fernmeldekontakte aber vergleichsweise niedrig war. E-Mails waren damals beispielsweise noch gar nicht von der Überwachung betroffen. Darüberhinaus wertete das Bundesverfassungsgericht auch das Verbot zur gezielten Überwachung einzelner Anschlüsse, das im G 10-Gesetz verfügt wird, und die Tatsache, dass eine Auswertung und Weitergabe der Informationen nur in wenigen Fällen erfolge, als weitere wichtige Gründe für die Vereinbarkeit des G 10-Gesetzes mit dem Grundgesetz:
„Auch wenn die freie Kommunikation, die Art. 10 GG sichern will, bereits durch die Erfassung und Aufzeichnung von Fernmeldevorgängen gestört sein kann, erhält diese Gefahr ihr volles Gewicht doch erst durch die nachfolgende Auswertung und vor allem die Weitergabe der Erkenntnisse. Insoweit kann ihr aber auf der Ebene der Auswertungs- und Übermittlungsbefugnisse ausreichend begegnet werden.“ (BVerfG, 1 BvR 2226/94 vom 14.7.1999, Absatz-Nr. 243)
Erfassung und Aufzeichnung bedrohen also schon die freie Kommunikation, Auswertung und Weitergabe aber, so sahen es die Verfassungsrichter, sind weitaus schlimmer. Es ist wie mit den Sicherheitskontrollen am Flughafen: je stärker sie die Objekte der Überwachung vereinzeln, je weniger sie maschinell sondern durch Personen erfolgen, desto unangenehmer sind sie.
Vom Filtern und Auswerten: Formale und inhaltliche Suchbegriffe
Die entscheidende Frage ist also: Ab wann liegt eine Auswertung vor, wann werden aus Signalen Informationen? Beschwerdeführer wie Verfassungsrichter waren sich gleichermaßen einig darin, dass eine Auswertung bei einem „computergestützten Wortbankabgleich“ (BVerfG, 1 BvR 2226/94 vom 14.7.1999, Absatz-Nr. 56), beim Filtern also, noch nicht vorliege. Das BVerfG-Urteil fiel freilich in eine Zeit des Umbruchs.

Innenhof der Gedenkstätte Bautzner Straße Dresden
Das G10-Gesetz stammt aus dem Jahr 1968 und damit aus einer Zeit, in der Daten zwar großflächig erhoben werden konnten, ohne dass es jedoch technisch möglich war, die Kommunikationsdaten einzelnen Kommunikationspartnern zuzuordnen und die Inhalte massenhaft automatisiert zu filtern. Dies hatte sich Ende der 1990er Jahre freilich schon geändert. Das Bundesverfassungsgericht wusste schon damals um die Aussagekraft der Verbindungsdaten:
„Ferner führt die Neuregelung zu einer Ausweitung in personeller Hinsicht. Zwar ist die gezielte Erfassung bestimmter Telekommunikationsanschlüsse gemäß § 3 Abs. 2 Satz 2 G 10 ausgeschlossen. […] Faktisch weitet sich der Personenbezug dadurch aus, daß es im Gegensatz zu früher heute technisch grundsätzlich möglich ist, die an einem Fernmeldekontakt beteiligten Anschlüsse zu identifizieren. (BVerfG, 1 BvR 2226/94 vom 14.7.1999, Absatz-Nr. 9)
Zudem wurde die Anwendung von G 10-Maßnahmen bei der Novelle auf weitere Delikte ausgeweitet: neben Gefahren eines bewaffneten Angriffs traten die Proliferation und der illegale Rüstungshandel, der internationale Terrorismus, Handel mit Rauschgift und Geldwäsche. Allesamt Gefahren, die „stärker subjektbezogen sind und auch nach der Darlegung des Bundesnachrichtendienstes vielfach erst im Zusammenhang mit der Individualisierung der Kommunikationspartner die angestrebte Erkenntnis liefern.“ (BVerfG, 1 BvR 2226/94 vom 14.7.1999, Absatz-Nr. 229)

Geruchskonserve in der Gedenkstätte Bautzner Straße Dresden
Man beruhigte sich freilich damit, dass nur sehr wenige Fernmeldevorgänge tatsächlich in der Auswertung landeten. Der Innenminister führte an, die „materiellen und personellen Ressourcen des Bundesnachrichtendienstes reichten […] nicht aus, das Aufkommen vollständig auszuwerten.“ (BVerfG, 1 BvR 2226/94 vom 14.7.1999, Absatz-Nr. 89) Lediglich 700 der 15.000 erfassten Fernmeldevorgänge würden mit Hilfe von Suchbegriffen selektiert, 70 würden von Mitarbeitern persönlich geprüft und 15 kämen in die Fachauswertung. Zwischen dem Filtern mit Hilfe von Suchbegriffen und dem Auswerten liegen also noch zwei Schritte. Wie aus den 700 Fernmeldevorgängen 70 werden, darüber schweigt der Innenminister. Anzunehmen ist, dass die gefilterteten Inhalte auf Suchwortkombinationen hin analysiert wurden.
Die Filterung erfolgt auch heute noch anhand formaler und inhaltlicher Suchbegriffe, die bei der Anordnung von G 10-Maßnahmen festgelegt werden. Formale Suchbegriffe sind „Anschlüsse von Ausländern oder ausländischen Firmen im Ausland“, inhaltliche Suchbegriffe sind „beispielsweise Bezeichnungen aus der Waffentechnik oder Namen von Chemikalien, die zur Drogenherstellung benötigt“ werden (BVerfG, 1 BvR 2226/94 vom 14.7.1999, Absatz-Nr. 87).
Suchen ist analysieren
Interessant an der Verhandlung über das G 10-Gesetz ist aber auch eine Aussage des Innenministers, in der er einräumt, dass die „Auswertung anhand der Suchbegriffe […] im Telex-Bereich vollautomatisch möglich“ (BVerfG, 1 BvR 2226/94 vom 14.7.1999, Absatz-Nr. 90) sei. Schon 1999 fand also eine automatische Auswertung statt, wenn auch aufgrund technischer Beschränkungen, nur in einem kleinen Bereich. Denn dieses Eingeständnis zeigt, dass die Trennung von Filterung und Auswertung, also von Suche und Analyse lediglich eine künstliche ist.
Für heutige automatische Textanalysen gilt: Suchen ist Analysieren. Wenn wir eine Anfrage an ein großes Textkorpus formulieren, dann fließen in diese Anfrage so komplexe Modelle über die Strukturierung und den semantischen Gehalt von Texten ein, dass jeder Anfrage faktisch eine Analyse zugrundeliegt. Um zu bestimmen, welche Themen in einem Dokument verhandelt werden, braucht man keinen Auswerter mehr; Topic Models schaffen Abhilfe.
In der Unterrichtung durch das Parlamentarische Kontrollgremium (PKGr) über die Durchführung sowie Art und Umfang von G 10-Maßnahmen im Jahr 2011 heißt es, lediglich ein eingeschränkter Teil internationaler Verkehre, der automatisiert stark gefiltert werde, unterliege der Aufklärung, nur
„ein geringer Anteil dieser E-Mails wird überhaupt manuell bearbeitet. […] Der deutliche Rückgang im Jahre 2011 ist auch darauf zurückzuführen, dass der BND das von ihm angewandte automatisierte Selektionsverfahren auch vor dem Hintergrund der Spamwelle im Jahre 2010 zwischenzeitlich optimiert hat. Hierzu haben unter anderem eine verbesserte Spamerkennung und -filterung, eine optimierte Konfiguration der Filter- und Selektionssysteme und eine damit verbundene Konzentration auf formale Suchbegriffe in der ersten Selektionsstufe beigetragen.“
Welche Verfahren genau zum Einsatz kommen, dazu schweigt der Bericht. Immerhin räumt er ein, dass Filterung und Selektion automatisch in einem mehrstufigen Verfahren erfolgen. Artikel 10, Absatz 4 des G 10-Gesetzes erlaubt es dem BND, bis zu 20% der auf den Übertragungswegen zur Verfügung stehenden Übertragungskapazitäten zu überwachen. 20% der Kapazitäten. Nicht 20% der tatsächlichen Kommunikation. Und zu den Kapazitäten schweigt sich der Bericht aus, auch zu den konkreten Zahlen der insgesamt erfassten Interaktionen. Sicher ist nur, dass sämtliche Formen der digitalen Kommunikation maschinell auswertbar sind: Telefongespräche, Faxe, Chatnachrichten, E-Mails, SMS etc.
Um aus einer so riesigen Datenmenge, wie sie in einem Jahr anfällt, eine vergleichsweise kleine Menge an Kommunikationsverkehren für die Auswertung herauszudestillieren — 329.628 Telekommunikationsverkehre im Bereich internationaler Terrorismus werden als auswertungswert erkannt, das sind weniger als 1000 pro Tag — reichen einfache Schlagwortsuchen nicht aus. Hierfür ist eine Modellierung von Themen anhand der Gewichtung und Distribution von Suchbegriffen nötig. Und dies auf allen erfassten Kommunikationsverkehren. Ein solches Verfahren ist nicht nur eine Filterung, sondern hat den Charakter einer Auswertung, es ist Suche und Analyse zugleich.
Die Dienste lesen nicht unsere E-Mails, sie wissen aber doch, was drin steht. Janosch lässt grüßen.
Definitionsmacht ohne Kontrolle
Die Auswertung geschieht zwar weitgehend automatisch. Das ist aber im Ergebnis kaum weniger schlimm, als wenn sie von einem Menschen vorgenommen würde. Denn „automatisch“ bedeutet natürlich nicht „objektiv“ oder „absichtslos“. Hinter der Auswahl der Suchbegriffe und der Modellierung von Themen stehen Vorstellungen von Gefahren und Gefährdern, die lediglich vor dem sehr engen Kreis der Mitglieder der G 10-Kommission und des Parlamentarischen Kontrollgremiums, Abgeordnete und Juristen, gerechtfertigt werden müssen. Davon abgesehen sind diese Vorstellungen so geheim wie die gewählten Suchbegriffe. Der BND besitzt hier eine Definitionsmacht, die sich einer gesellschaftlichen Debatte oder Kontrolle und einer wissenschaftlichen Prüfung entziehen kann. Diese Vorstellungen zählen zu den Arcana Imperii. Denn die Logik der Überwachung ist selbst Teil dessen, was aus Sicht der Überwacher geschützt werden muss.

Verhörraum Gedenkstätte Bautzner Straße Dresden
Der Vergleich hinkt zwar, ist aber dennoch bedenkenswert: Wie wäre es, wenn man das StGB geheimhalten würde mit der Begründung, dann wüssten ja potenzielle Kriminelle, welche Handlungen als kriminell gelten und daher zu vermeiden wären? Dies erscheint uns deshalb so absurd, weil das StGB gewissermaßen der Maßstab ist, an dem wir messen, ob jemand kriminell oder straffällig geworden ist. Wäre das StGB unveröffentlicht, dann wäre Kriminellsein nicht etwas, das sich (auch für den potenziell Kriminellen) anhand dieses Maßstabs bestimmen ließe, sondern eine Eigenschaft der Personen, die sich in Taten aktualisieren kann, aber nicht muss. So sehr der Vergleich auch hinkt, so macht er doch sichtbar, dass die Dienste Identitäten nach demselben Muster zuschreiben: ein „Gefährder“ oder „Terrorist“ ist nicht erst dann ein Terrorist, wenn er zuschlägt oder zugeschlagen hat. Er ist es schon vor der Tat. Er ist identifizierbar durch seine Sprache, die auf künftige Taten auch dann verweisen kann, wenn sie die Tat nicht einmal zum Thema hat. Und diese Zuschreibung erfolgt in einem Feld, in dem die Zuschreibungen an weitergehende Überwachungs- und Strafregime gebunden sein kann. Wie würden wir es finden, wenn der Bundesgrenzschutz die Liste von Gegenständen, die auf Flugreisen nicht im Gepäck mitgeführt werden dürfen, geheimhalten würde? Und wenn der Bundesgrenzschutz aufgrund von Verstößen gegen diese Liste Passagieren das Fliegen verweigern könnte, ohne sagen zu müssen, warum?
Die strategische Fernmeldeüberwachung ist durch den technisch-informatischen Fortschritt so effizient geworden, dass ihre rechtliche Grundlage fragwürdig geworden ist. Die Macht, zu definieren, wer „Terrorist“ oder „Gefährder“ ist, darf daher nicht länger ohne Kontrolle bleiben.