

Content Mapping mit Topic Models
Liebe Freunde der Sicherheit,
in einem früheren Beitrag habe ich argumentiert, dass die „inhaltlichen Suchbegriffe“, die der BND beim „Filtern“ des Internet benutzt, über Topic Models oder ähnliche Verfahren dazu genutzt werden können, Kommunikation thematisch zu analysieren. Das „Filtern“ bei der strategischen Fernmeldeüberwachung wäre dann faktisch eine Analyse, für die das Bundesverfassungsgericht hohe Hürden gesetzt hat. Heute möchte ich zeigen, wie die Kombination von Topic Models und Metadaten dazu eingesetzt werden kann, thematische Profile von politischen Szenen zu berechnen.
Was sind Topic Models?
Topic Models sind Algorithmen zur Aufdeckung thematischer Strukturen in Texten. Sie gewichten und messen die Affinität von Inhaltswörtern in Textexemplaren eines Korpus. Häufig miteinander auftretende Wörter, die eine hohe Themenspezifizität aufweisen, werden als „Topics“ interpretiert. Diese Lexemcluster haben keine Namen; ihre Benennung ist ein Akt der Interpretation. Ebenso erfolgt die Ermittlung der Anzahl der Topics in den Standardverfahren nicht datengeleitet, sondern in Abhängigkeit von Festlegungen des Forschers.
Meinungsbilder aus dem Internet
Das Innenministerium ließ verlauten: „Wir brauchen eine belastbare Erfassung von Meinungs- und Stimmungslagen der Bevölkerung. Es liegt kein Eingriff in das allgemeine Persönlichkeitsrecht vor, wenn eine staatliche Stelle im Internet verfügbare Kommunikationsinhalte erhebt, die sich an jedermann oder zumindest an einen nicht weiter eingrenzbaren Personenkreis richten.“ Die Folge: alle Nachrichtendienste investieren in die open source intelligence.
Über welche Themen diskutieren linke Szenen?
Will man beispielsweise wissen, womit sich linke Szenen im deutschsprachigen Raum beschäftigen, kann man eine linke News-Site wie http://linkunten.indymedia.org auf ihre Topics hin analysieren. Auf der Subdomain von indymedia.org werden nach Meinungsverschiedenheiten in der Redaktion von Indymedia Deutschland und dem Bedürfnis nach einer engeren Verntezung süddeutscher Szenen Nachrichten veröffentlicht. Das Portal ist inzwischen aktiver als das deutschsprachige indymedia.org. Auch wenn grundsätzlich Nachrichten aus allen Regionen veröffentlicht werden, liegt ein spezieller Fokus auf dem südwestdeutschen Raum. Wendet man auf sämtliche dort publizierten Texten Topic Modelling an, ordnet sich der Wortschatz aufgrund seiner Distribution in folgende Gruppen, für die relativ leicht Namen gefunden werden können:
Themenschwerpunkte linker Szenen
Weil die Artikel auf http://linkunten.indymedia.org unter anderem nach Regionen verschlagwortet sind, ist es möglich, für einzelne linke Szenen Topic-Profile zu erstellen und die Intensität der Aktivitäten zu berechnen. Die unten stehende Grafik zeigt das Topic-Profil der Dresdner Szenen im Vergleich zu anderen Szenen in Deutschland. Sie zeigt die Differenz zum Durchschnitt der normalisierten relativen Auftretenshäufigkeiten der jeweiligen Topics im Gesamtkorpus.
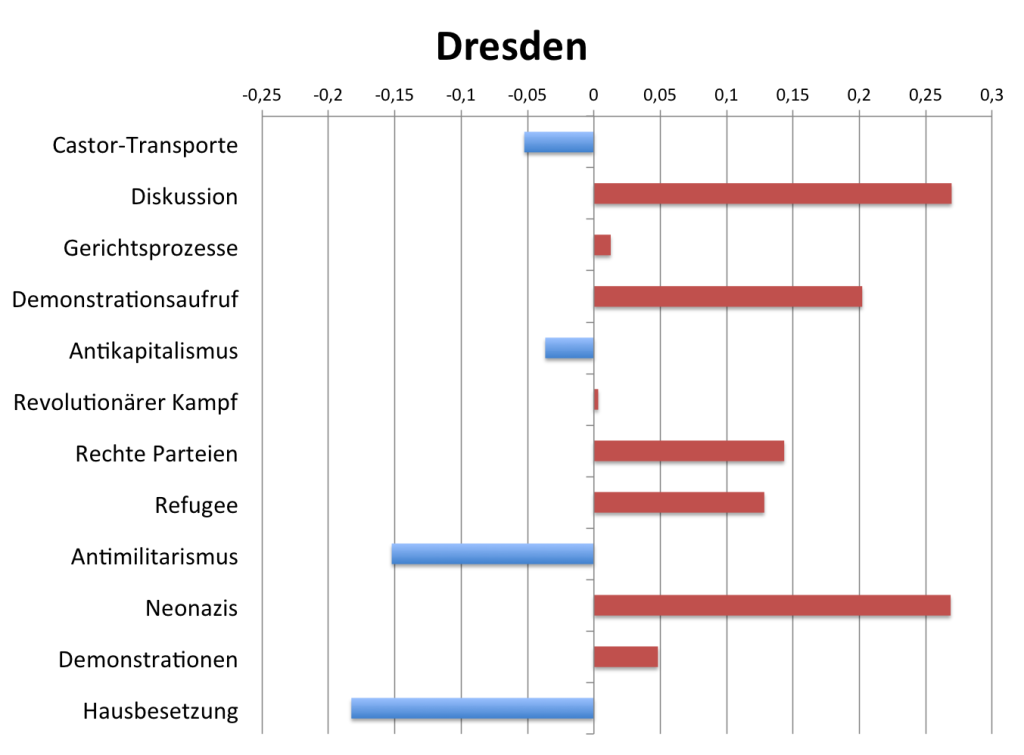
In Dresden wird demnach überdurchschnittlich häufig über Neonazis, rechte Parteien und Flüchtlinge berichtet, zu Demonstrationen aufgerufen und über Diskussionen in und außerhalb der Szene berichtet. Antimilitarismus und Hausbesetzungen spielen hingegen eine vergleichsweise geringe Rolle.
Interessiert man sich für einen Vergleich von Szenenprofilen, kann man die Themendistributionen in Spinnengrafiken übereinanderlegen, wie im folgenden Beispiel für Wien und Salzburg:
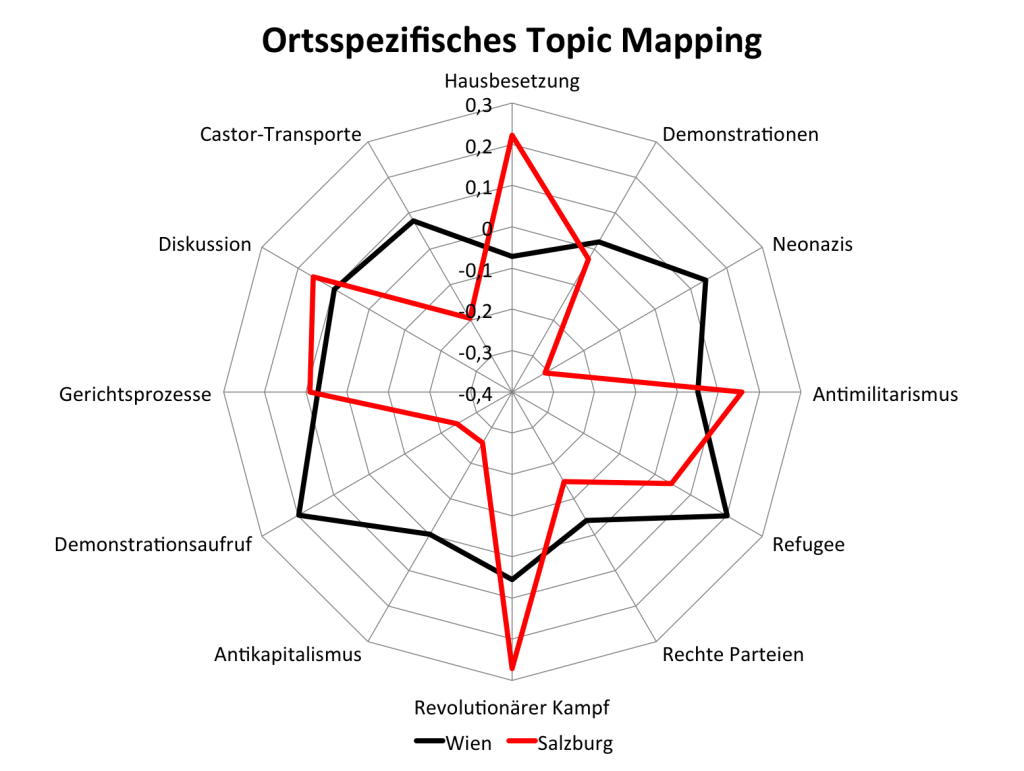
Ebenso ist es möglich, die Affinität einzelner Szenen zu relevanten Topics zu analysieren. Von besonderem Interesse für Sicherheitsbehörden könnte ja beispielsweise das Topic „Revolutionärer Kampf“ sein. Eine Analyse der ortsspezifischen Frequenz dieses Topics im Korpus ergibt folgendes Städteranking:
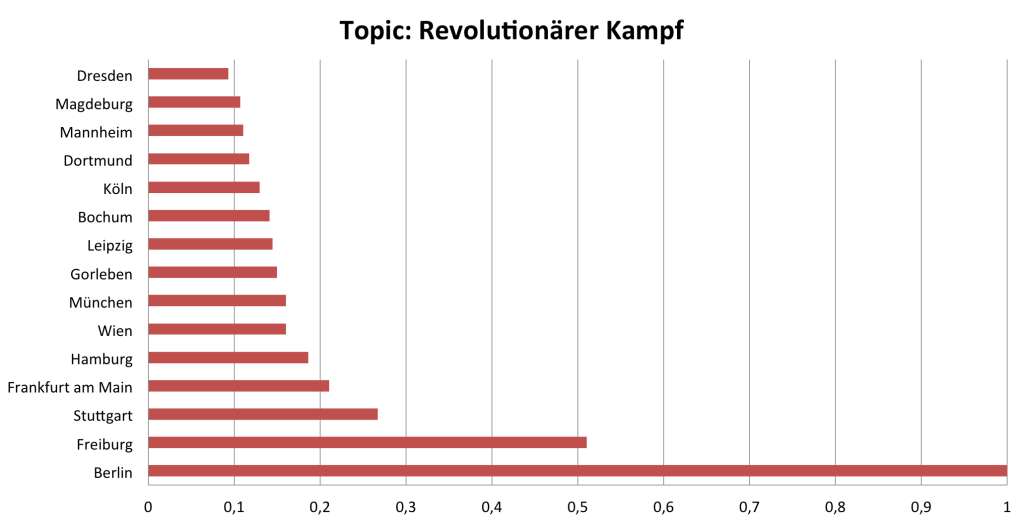
Topic Models sind ein eleganter Weg, um sich mit relativ einfachen Mitteln einen Überblick über die inhaltlichen Prägungen von Korpora zu verschaffen. Maßnahmen gegen Topic Models laufen ins Leere, außer man ist bereit, auf inhaltlich kohärente Diskussionen zu verzichten.
Die Buchlesemaschine des Bundesamtes für Verfassungsschutz
Liebe Freunde der Sicherheit,
Lesen bildet zwar, aber in Zeiten der Digitalisierung kann Lesen viel effizienter durch Automaten erledigt werden. Dass unsere Dienste auch hier an der Spitze der technologischen Entwicklung stehen, belegt ein Dokument, auf das mich ein Kollege aufmerksam gemacht hat. In der 29. Sitzung des 2. Parlamentarischen Untersuchungsausschusses am 13. September 2012 spielte ein offenbar im Selbstverlag publiziertes Buch eine Rolle.

Scanroboter im Digitalisierungszentrum der SLUB
In diesem 2004 erschienenen Buch, das von einer Person verfasst wurde, die sich dem Landesamt für Verfassungsschutz in Baden-Württemberg vorher bereits als Informant andiente, tauchte neben Referenzen auf eine rechtsterroristische Zelle namens NSU auch der Name eines Beamten des Landesamtes für Verfassungsschutz in Baden-Württemberg auf. Die Aussage dieses LfV-Beamten, Günter Stengel, bringt es ans Tageslicht: Das Bundesamt für Verfassungsschutz digitalisiert Schriften und durchsucht sie nach „Begriffen“. Darunter sind einerseits die Arbeitsnamen von Mitarbeitern, aber offenbar auch Schlagwörter. Hier Ausschnitte des Wortlautprotokolls:
Clemens Binninger (CDU/CSU): Woher haben Sie denn erfahren, dass der ein Buch publiziert oder ein Buch schreibt und das an Gott und die Welt schickt? Woher haben Sie das dann erfahren?
Zeuge Günter Stengel: Ich glaube, das habe ich vom BfV erfahren. Die haben so eine Buchlesemaschine auf bestimmte Wörter. Da war Arbeitsname – so ist es rausgekommen — war mein Arbeitsname dabei.
Clemens Binninger (CDU/CSU): Ach, die sichten die Bücher, ob in Büchern irgendwas über LfV-Leute oder BfV-Leute steht?
Zeuge Günter Stengel: Wahrscheinlich hat er sich dorthin auch gewandt, an diese Stelle, und irgendeine Dienststelle hat das Buch dann von ihm zugeschickt bekommen. Ich weiß noch, dass dann ein Schreiben kam: Hier ist schon wieder ein Vermerk von diesem Stauffenberg, ein Buch geschrieben, und Sie vom LfV Baden-Württemberg sind persönlich genannt.
Clemens Binninger (CDU/CSU): Aber so was müsste doch auch irgendwo in den Akten des LfV zu finden sein. Also, jetzt sind wir ja in einem anderen offiziellen Vorgang. Quasi zum Eigenschutz der Behörde werden Bücher im Prinzip durchgeguckt: Wird irgendwo einer unserer Mitarbeiter enttarnt? Sie haben ja alle Arbeitsnamen, sind zwar keine V-Leute, aber haben Arbeitsnamen. Wenn das der Fall ist, gibt es eine kurze Meldung an das jeweilige Landesamt: Achtung, in diesem oder jenen Buch wird Herr oder Frau XY genannt. – Ist so das Verfahren?
Zeuge Günter Stengel: Ja, so muss das gewesen sein. Ich weiß, dass in dem Buch – – Es sind auch viele Politikernamen genannt worden und LfV Baden-Württemberg. Er schreibt dann, was ich damals zu einer be- stimmten Sache angeblich geredet habe, und dann hat er sich an den MAD gewandt, und der hätte gar das Gegenteil von mir gesagt. […]
Clemens Binninger (CDU/CSU): Gut. Wir haben ja nachher noch jemanden da, der sich mit den normalen Arbeitsabläufen eigentlich am besten auskennen müsste. Den können wir ja dann auch noch mal fragen, ob es da ein eingespieltes Verfahren gibt, wie mit solchen Verdachtshinweisen oder – – „Verdacht“ ist falsch – aber so Enttarnungshinweisen oder -gefahren umgegangen wird, ob es so ein standardisiertes Verfahren gibt und Sie dann benachrichtigt werden. Titel hat man Ihnen nie gesagt. Können Sie sich auch nicht erinnern?
Zeuge Günter Stengel: Nein. Im Gegensatz zu anderen Begriffen ist mir das nicht im Gedächtnis geblieben.
Clemens Binninger (CDU/CSU): Werden dann solche Bücher asserviert? Ich meine, die Behörden heben ja im Zweifel alles auf, was nur irgendwie ein bisschen relevant ist. Oder meinen Sie, gescannt und gelesen, dann weggeschmissen?
Zeuge Günter Stengel: Das weiß ich nicht.
Clemens Binninger (CDU/CSU): Wissen Sie nicht.
Zeuge Günter Stengel: Kann ich nichts dazu sagen.
Ich freue mich natürlich, dass auch das BfV seinen Beitrag dazu leistet, dass die Digitalisierung unserer Bucharchive nicht allein in der Hand amerikanischer Großkonzernen wie Google liegt.
30C3 Nachlese, Teil 2
Auf vielfachen Wunsch hier die gif-Grafik, die ich zur Illustration der Hoffnung einiger Aktivisten erstellt habe, die NSA suche lediglich nach Keywords.

Wie die NSA nicht unsere E-Mails liest (CC0 1.0 Universell, Font by Bolt)
In der letzten Sendung von Breitband auf DeutschlandradioKultur gab es einen schönen Beitrag von Marcus Richter zur Zukunft der Überwachung, der auf dem Kongress entstanden ist und in dem ich auch was sagen durfte.
Und dann habe ich — wie beinahe alle Vortragenden — ein Interview für dctp.tv gegeben, bei dem zumindest die erste Hälfte von meiner Seite komplett misslungen ist. Der zweite Teil enthält aber ein paar Punkte, die ich im Talk nicht so deutlich formuliert habe:
Das Medienimage der Polizei im SPIEGEL
Liebe Freunde der Sicherheit,
Anfang der Woche war ich bei einer Polizei-Tagung der Evanglischen Akademie Hofgeismar zum Thema „Demokratie auf der Straße -‚Gutbürger trifft Gutpolizisten'“ eingeladen, um über das Medienimage der Polizei zu sprechen. Eine interessante Veranstaltung, bei der sich Aktivisten, Polizisten und Wissenschaftlerinnen in ungezwungener Atmosphäre begegnen und austauschen konnten. Bei meinem Vortrag zeigte sich, dass das Image der Polizei in den Medien nicht übereinstimmt mit dem Vertrauen, das ein großer Teil der Deutschen in die Insitution der Polizei hat. Denn in den Medien ist die Polizei der Prügelknabe — und dies in doppelter Hinsicht. Das habe ich versucht, am Beispiel des Spiegel (Print und SPON) zu illustrieren.
Allgemeine Frequenzentwicklung
Auch wenn jüngere Zeitgenossen glauben, die Polizei habe in den letzten Jahren wegen Stuttgart 21 und NSU-Desaster im Fokus der Berichterstattung gestanden, relativiert ein Blick auf die Verteilung der Lemmata „Polizei“, „Polizist“, „Polizeibeamter“ und „Ordnungshäter“ im Printarchiv des SPIEGEL diese Einschätzung.
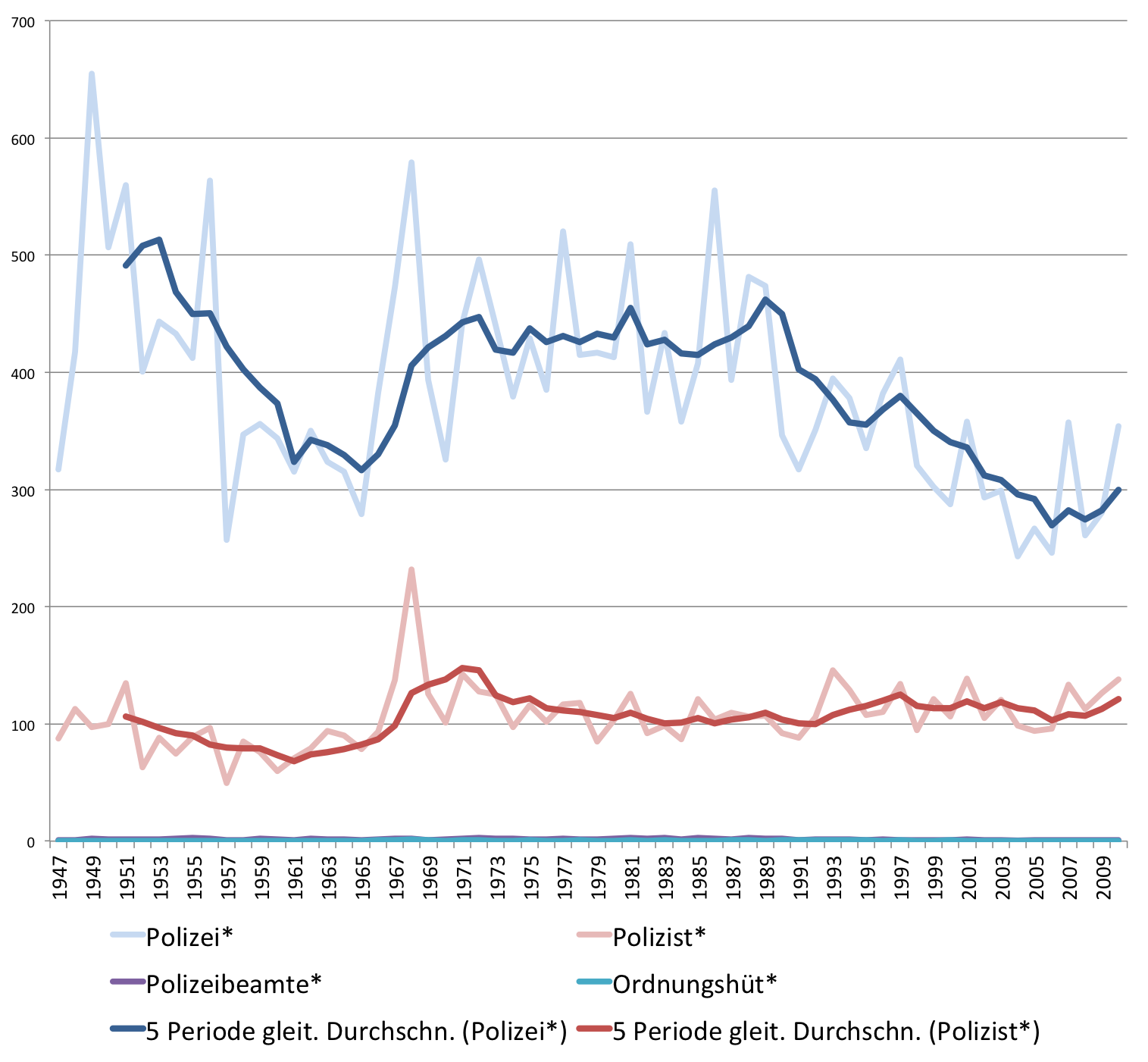
Verteilung von Bezeichnungen für Polizisten im Print-Archiv des SPIEGEL
Frequenz je 100.000 Wörter; auch bei allen folgenden Grafiken
Im langfristigen Trend geht die Berichterstattung über die Polizei zurück, auf Polizisten wird in etwa gleich häufig Bezug genommen. Auch wenn man sich die Berichterstattung über die Polizei auf Spiegel Online, Politik Inland, anschaut, zeigt sich, dass die Berichterstattung über die Polizei an einzelne Ereignisse gebunden ist und langfristig nicht zugenommen hat.
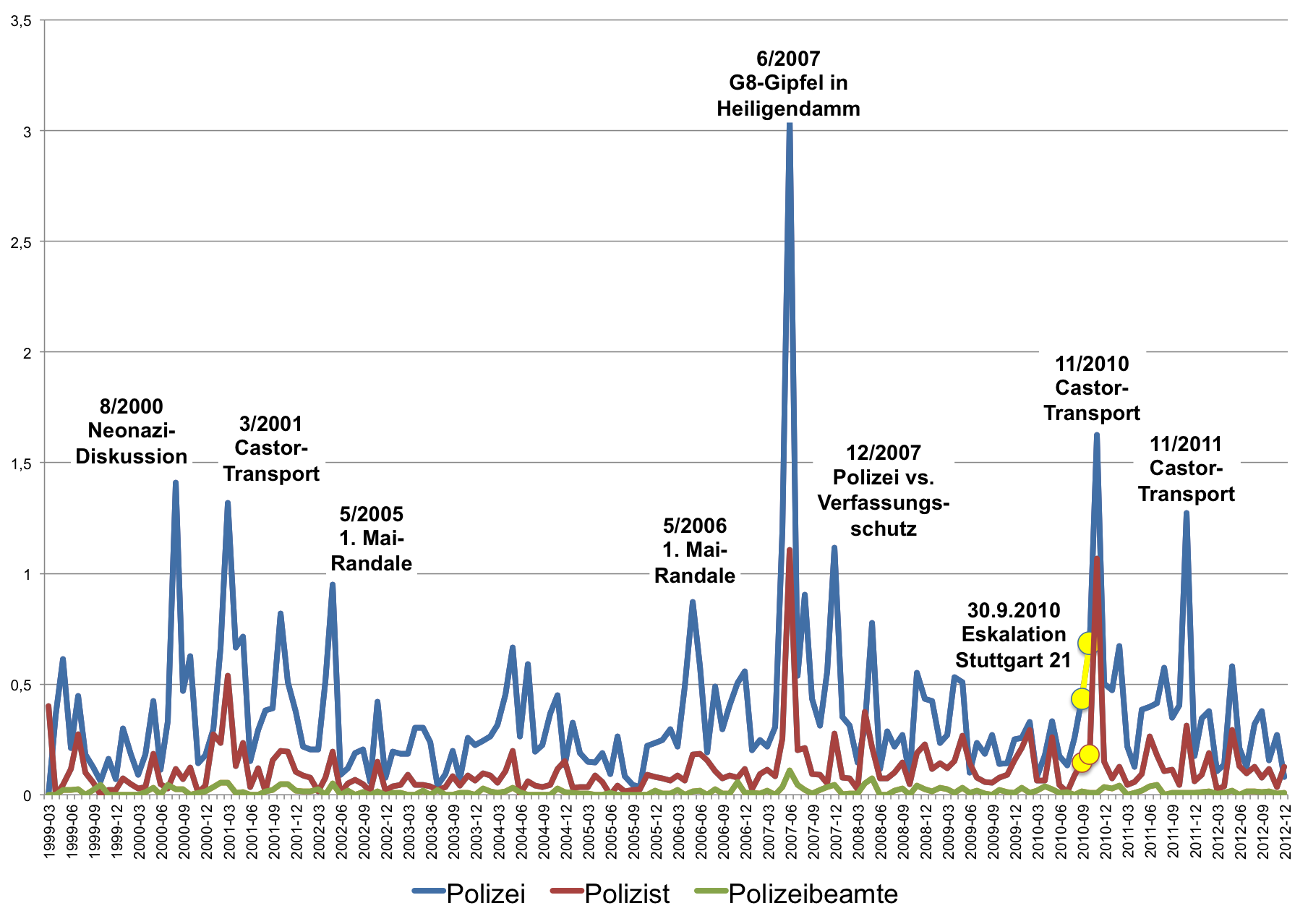
Entwicklung der Frequenz der Bezeichnungen von Polizei auf SPON (Politik, Inland)
Interessant ist hier, dass die Berichterstattung über die Polizei nach der Eskalation in Stuttgart (im Graphen gelb markiert) von der Berichterstattung über die Castor-Transporte deutlich in den Schatten gestellt wird.
Wie wichtig die Protestbewegungen um 1968 für die Polizeiberichterstattung waren zeigt die folgende Grafik, die visualisiert, wie viele unterschiedliche Wörter mit dem Lexem „polizist“ pro Jahr im Spiegel gebildet wurden und wie häufig diese Komposita relativ zur Anzahl der Wörter benutzt wurden.
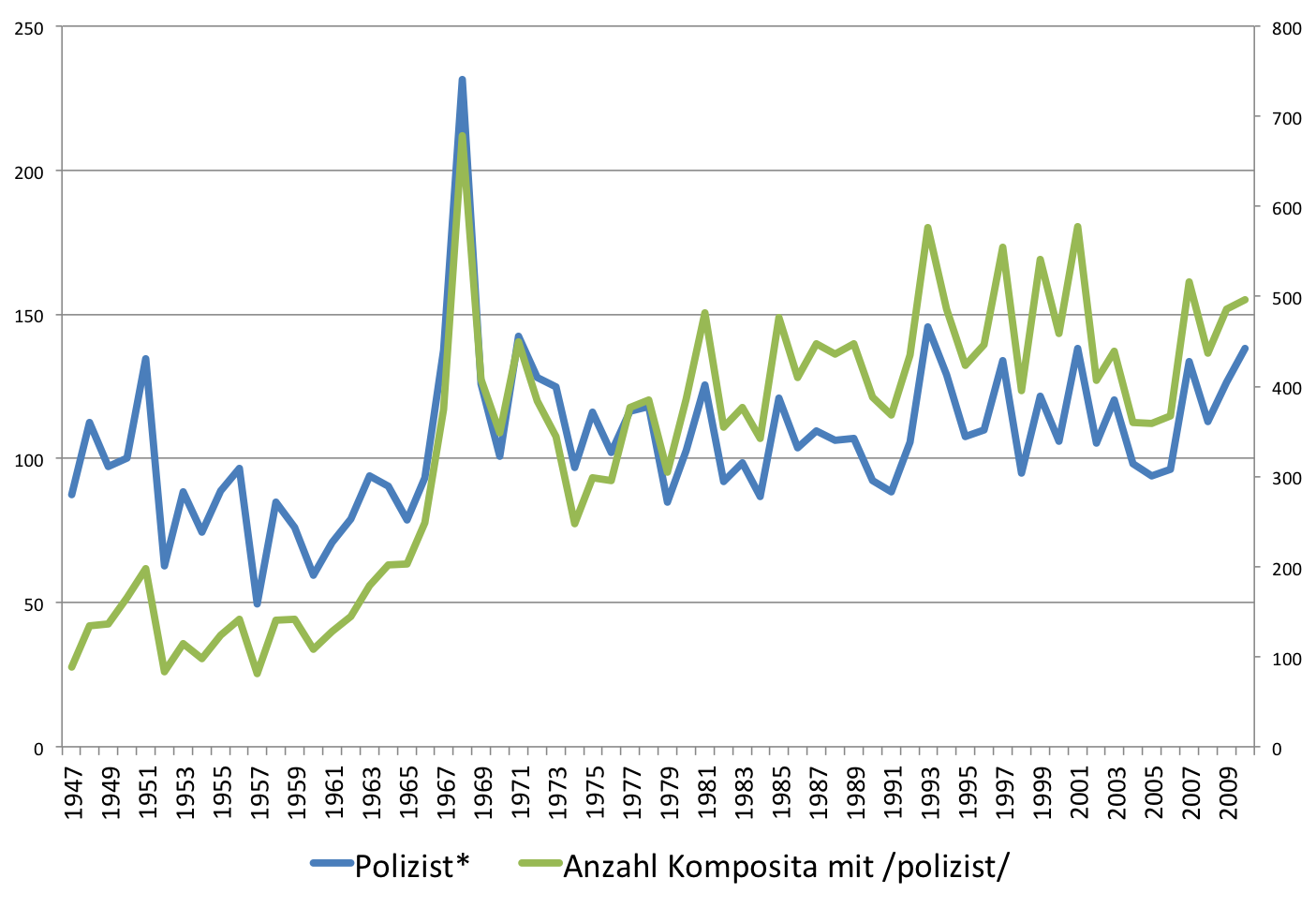
Komposita mit dem lexikalischen Morphem „polizist“:
Entwicklung von Token (linke Achse) und Types (rechte Achse)
Es zeigt sich, dass die Ereignisse um 1968 die Ursache dafür waren, dass der polizeispezifische Wortschatz in den Medien sich ausdifferenziert hat.
Polizeiliche Mittel
Was wird zum Thema, wenn der SPIEGEL über die Polizei schreibt? Da sind zuallererst einmal polizeiliche Instrumente zur Manifestation des staatlichen Gewaltmonopols zu nennen, beispielsweise der Wasserwerfer:
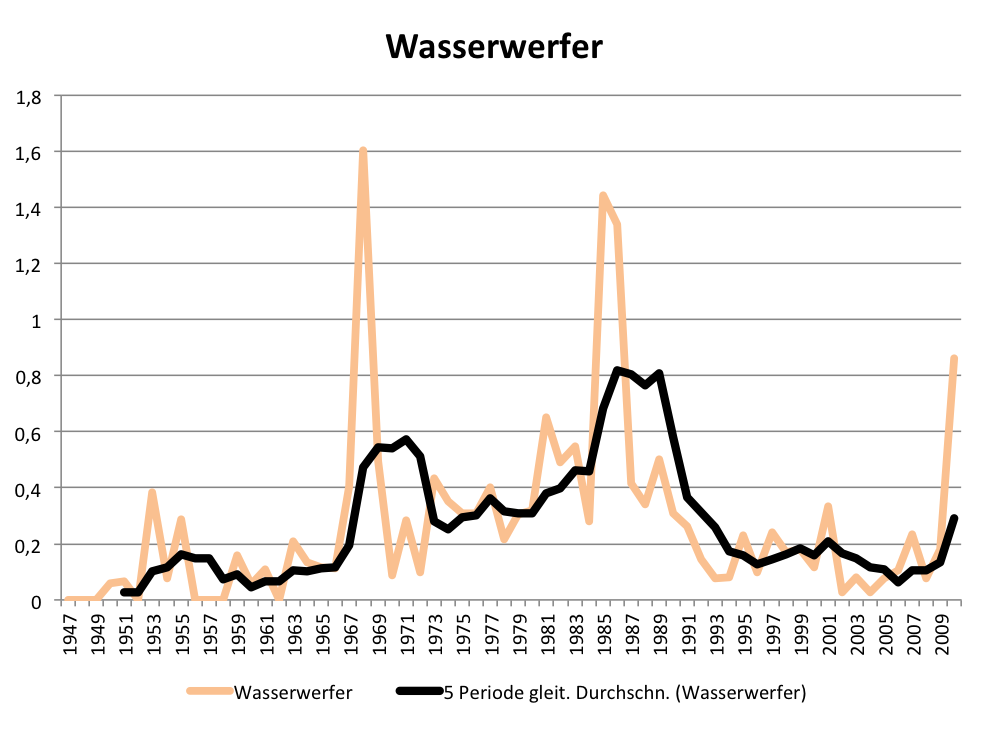
Konjunkturen der Berichterstattung über Wasserwerfer
Die Verlaufskurve reflektiert einige Höhepunkte der Protestgeschichte der BRD: die 68er-Bewegung, die Anti-AKW-Bewegung, die Friedensbewegung und die Proteste gegen die Startbahn West in Frankfurt. Parallel zum Wasserwerfer entdeckte die Presse auch den Polizeiknüppel und den Schlagstock. Erich Duensings geflügeltes Wort vom „Leberwurst-Prinzip — in der Mitte hineinstechen und nach beiden Seiten ausdrücken“ als polizeiliche Taktik für die Auflösung der Demonstration anlässlich des Schah-Besuchs am 2. Juni 1967 und das Kommando „Knüppel frei“ sind ins kollektive Gedächtnis eingegangen.

Ein beliebter Gegenstand der Berichterstattung um 1968: der Schlagstock
Die absoluten Maxima um 1968 sind auch ein Indikator dafür, dass Schlagstock- und Wasserwerfereinsatz damals in dieser Dimension noch neu waren und die Polizei angesichts der Konfrontation mit Gewalt und Gegengewalt erst mit ihrer Aufrüstung begann. Eine Aufrüstung, die Ende der 1990er auch zur Aufnahme von Pfefferspray in das Repertoire der Einsatzmittel führte.
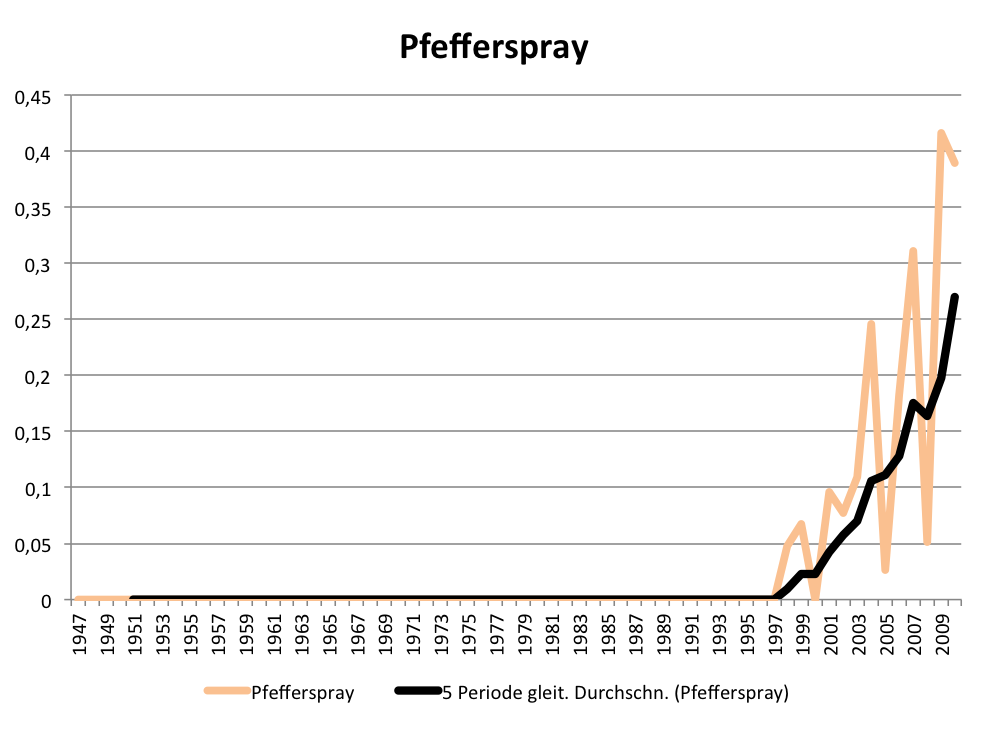
Der Einsatz von Pfefferspray wird seit Ende der 1990er zum Thema im SPIEGEL
Polizeiliche Mittel
Insgesamt muss man aber festhalten, dass in den letzten Jahre deutlich seltener über Polizeieinsätze mit Schlagstock oder Wasserwerfereinsatz berichtet wurde. Auch Komposita, die Polizei in negativer Weise mit dem Einsatz von Gewalt in Verbindung bringen, nehmen im SPIEGEL tendenziell ab:
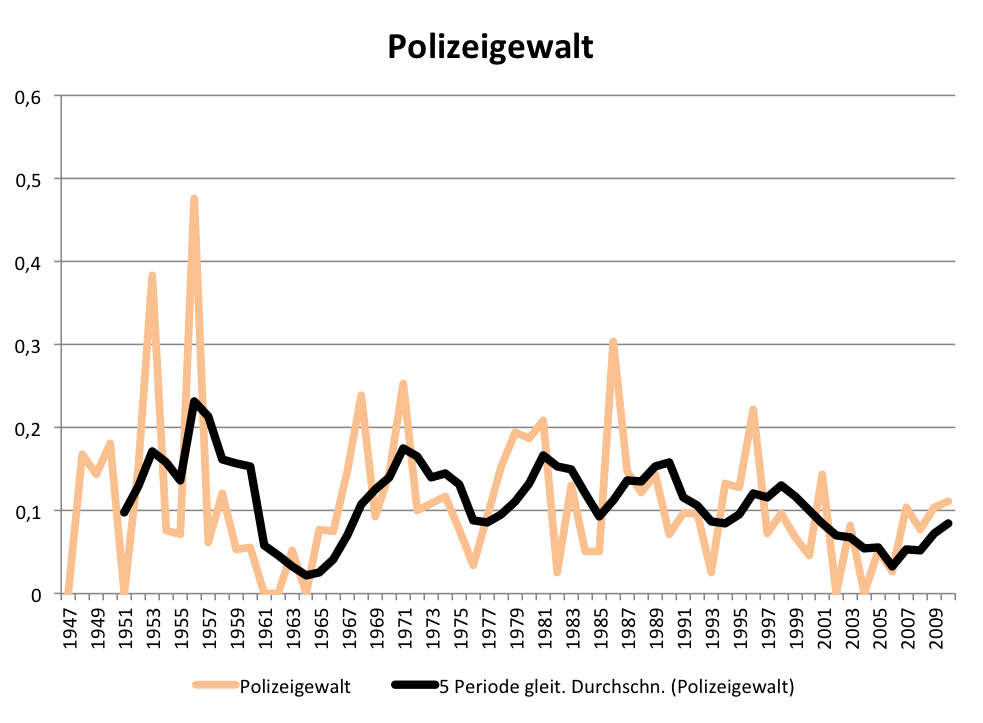
Frequenz des Lemmas „Polizeigewalt“ im Printarchiv des SPIEGEL
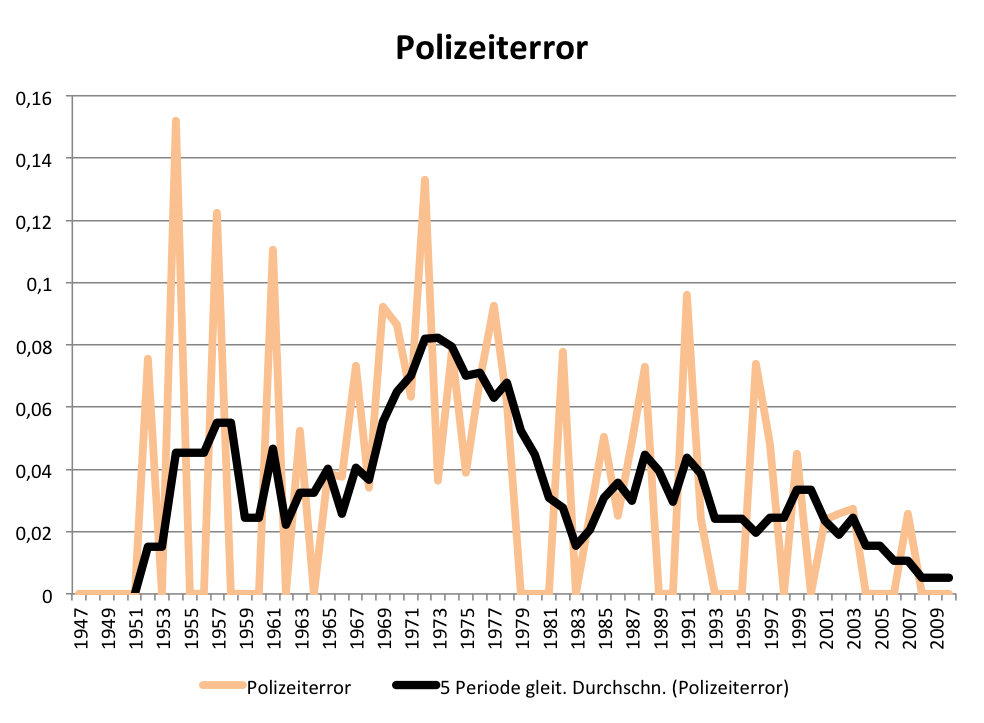
Frequenz des Lemmas „Polizeiterror“ im Printarchiv des SPIEGEL
Daraus zu schließen, dass die Polizei nun in positivem Licht dargestellt wird, ist aber falsch. Wenn Spiegel Online über die Polizei berichtet, dann signifikant häufig im Kontakt des Einsatzes von Gewalt, wobei die Polizei sowohl Ziel als auch Quelle der Gewaltausübung ist. Und diese Verbindung bleibt in fast allen Jahrgängen von SPON und Spiegel print seit den 1960er Jahren stabil.
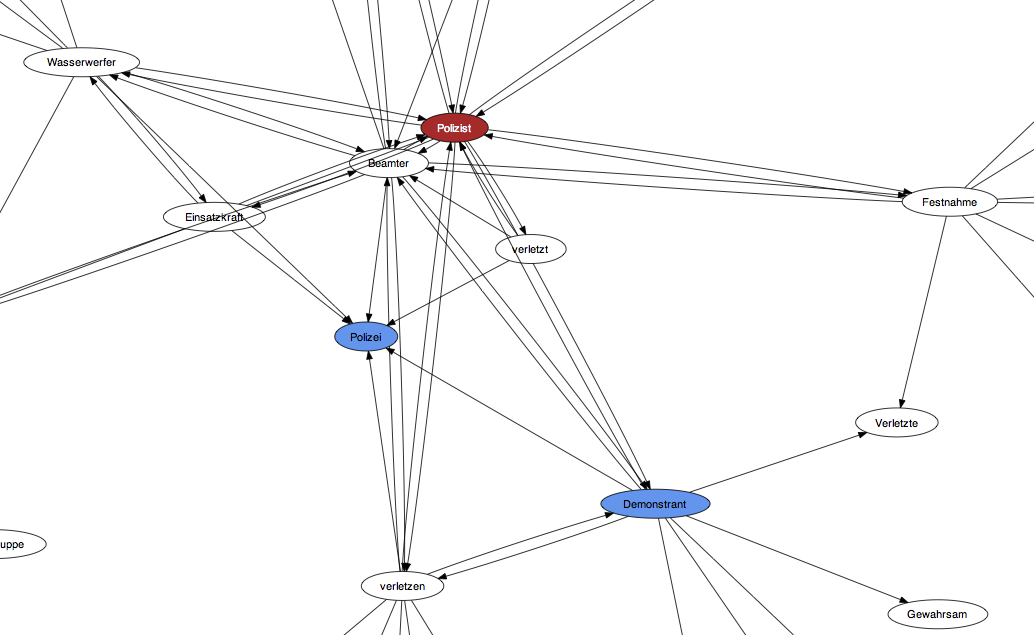
Kollokationen zum Lemma „Polizist“ in Spiegel Online (Politik Inland) im Jahr 2011
Trotz ihres guten Images in der Bevölkerung wird die Polizei in Medien wie dem SPIEGEL also stereotyp mit dem Einsatz von Gewalt assoziiert. Umgekehrt gilt dies auch für Demonstranten, über die vorwiegend nur dann berichtet wird, wenn physische Gewalt im Spiel ist. Dass die Repräsentationslogik der Medien eine Legitimationsmöglichkeit für die Eskalation von Gewalt auf Demonstrationen bietet, liegt auf der Hand. Für die Polizei gilt: keine Presse ist gute Presse.
Off Topic 2: Noch mehr Fakten zu SPIEGEL Online
Liebe Freunde der Sicherheit,
semantisch bestimmte Wort- und Phrasenklassen lassen sich natürlich nicht nur zur Aufdeckung subversiver Tätigkeiten benutzen, sondern auch für ganz unnütze Dinge, etwa zur Analyse von Online-Medien. Im vorletzten Posting habe ich mir die Ressortentwicklung bei SPIEGEL-Online angeschaut und herausgefunden, was wir ohnehin schon alle wussten: das von uns so geliebte Ressort „Panorama“ wurde in den letzten 10 Jahren langsam aber stetig ausgebaut, so dass es inzwischen sogar mehr Artikel umfasst als Politik-Inland oder Politik-Ausland.
Heute möchte ich euch ein paar Zeitreihen zeigen, die man getrost als Indikator für journalistische Qualität ansehen kann. Die Zeitreihen wurden mit vergleichsweise einfachen Mitteln berechnet: Der Angstindex (man könnte ihn auch Fnordbarometer) zeigt die Anzahl von Wörtern und Wendungen an, die auf einschüchternde Sachverhalte hinweisen (Terror, Seuchen, Umweltkatastophen, Islamisten, Wirtschaftskrisen etc.). Wortschatzkomplexität habe ich mit dem Maß Yule’s K operationalisiert. Der Manipulativitätsindex setzt sich zusammen aus der Anzahl aus Wörtern und Phrasen, die auf Vermutungen bzw. unsicheres Wissen hinweisen (auch Mutmaßungsindex), der Anzahl metasprachlich markierter Wendungen (z.B. sogenannte freie Wahlen) und einer Reihe von Emotionalitätsindikatoren. Der Skandalisierungsindex beruht auf einer Taxonomie, die Lemmata (vor allem Verben und Adjektive) mit starken deontischen Dimensionen erkennbar macht. Die Wort- und Phrasenlisten wurden mit Hilfe maschineller Lernverfahren ermittelt.
Betrachtet man die Entwicklung von SPON von 2000-2010 so fällt zunächst auf, dass die durchschnittliche Wortschatzkomplexität pro Artikel im Trend allmählich abgenommen hat:

Durchschnittliche Wortschatzkomplexität je Artikel in SPIEGEL-Online
Dafür nehmen die Indikatoren für einen stärker mutmaßenden, d.h. weniger faktengesättigten, und skandalisierenderen journalistischen Stil nach und nach zu:

Skandalisierung- und Mutmaßungsindex für SPIEGEL-Online
Der Manipulativitätsindex im Ressort Politik verharrt seit Mitte 2009 auf einem Niveau, den er zwischenzeitlich nur kurz nach den Terroranschlägen auf das World Trade Center hatte:

Manipulativitätsindex für SPIEGEL-Online, Ressort Politik
Interessant ist, dass der Angstindex im Ressort Wirtschaft den politischen Angstindex, der seit 9/11 auf erhöhtem Niveau verharrt, zweitweise im Zuge der Subprime-Krise überholt hat.

Fnord-Index für SPIEGEL-Online, Ressorts Politik und Wirtschaft
Diese Einsicht scheint zwar zunächst trivial, ist aber doch bemerkenswert, wenn man bedenkt, dass für den SPIEGEL die größte Gefahr nicht mehr von Terroristen, sondern von der Hochfinanz ausgeht.